Contents
Le domaine des statistiques est divisé en deux grandes divisions : descriptive et inférentielle. Chacun de ces segments est important, offrant des techniques différentes qui permettent d’atteindre des objectifs différents. Les statistiques descriptives décrivent ce qui se passe dans une population ou un ensemble de données. Les statistiques inférentielles, en revanche, permettent aux scientifiques de prendre les résultats d’un groupe échantillon et de les généraliser à une population plus large. Les deux types de statistiques présentent des différences importantes.
Statistiques descriptives
Les statistiques descriptives sont le type de statistiques qui vient probablement à l’esprit de la plupart des gens lorsqu’ils entendent le mot « statistiques ». Dans cette branche des statistiques, l’objectif est de décrire. Les mesures numériques sont utilisées pour décrire les caractéristiques d’un ensemble de données. Un certain nombre d’éléments appartiennent à cette partie des statistiques, comme par exemple
Ces mesures sont importantes et utiles car elles permettent aux scientifiques de voir des schémas parmi les données, et donc de donner un sens à ces données. Les statistiques descriptives ne peuvent être utilisées que pour décrire la population ou l’ensemble de données à l’étude : Les résultats ne peuvent être généralisés à aucun autre groupe ou population.
Types de statistiques descriptives
Il existe deux types de statistiques descriptives utilisées par les chercheurs en sciences sociales :
Les mesures de la tendance centrale saisissent les tendances générales des données et sont calculées et exprimées sous forme de moyenne, de médiane et de mode. La moyenne indique aux scientifiques la moyenne mathématique de l’ensemble des données, comme l’âge moyen du premier mariage ; la médiane représente le milieu de la distribution des données, comme l’âge qui se situe au milieu de la fourchette des âges auxquels les gens se marient pour la première fois ; et le mode peut être l’âge le plus courant auquel les gens se marient pour la première fois.
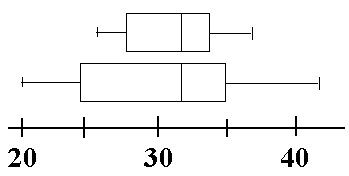
Les mesures de diffusion décrivent la manière dont les données sont distribuées et sont liées les unes aux autres, notamment :
- La gamme, l’ensemble des valeurs présentes dans un ensemble de données
- La distribution de fréquence, qui définit combien de fois une valeur particulière se produit dans un ensemble de données
- Quartiles, sous-groupes formés au sein d’un ensemble de données lorsque toutes les valeurs sont divisées en quatre parties égales dans l’intervalle
- Écart moyen absolu, la moyenne de l’écart de chaque valeur par rapport à la moyenne
- L’écart, qui illustre l’ampleur de la dispersion des données
- L’écart-type, qui illustre la dispersion des données par rapport à la moyenne
Les mesures de la propagation sont souvent représentées visuellement dans des tableaux, des diagrammes circulaires et à barres, et des histogrammes pour aider à comprendre les tendances des données.
Statistiques inférentielles
Les statistiques inférentielles sont produites par des calculs mathématiques complexes qui permettent aux scientifiques de déduire des tendances sur une population plus large à partir de l’étude d’un échantillon prélevé sur celle-ci. Les scientifiques utilisent les statistiques inférentielles pour examiner les relations entre les variables au sein d’un échantillon et ensuite faire des généralisations ou des prédictions sur la façon dont ces variables se rapporteront à une population plus large.
Il est généralement impossible d’examiner chaque membre de la population individuellement. Les scientifiques choisissent donc un sous-ensemble représentatif de la population, appelé échantillon statistique, et à partir de cette analyse, ils sont en mesure de dire quelque chose sur la population d’où provient l’échantillon. Il existe deux grandes divisions de la statistique inférentielle :
- Un intervalle de confiance donne une plage de valeurs pour un paramètre inconnu de la population en mesurant un échantillon statistique. Il est exprimé en termes d’intervalle et de degré de confiance que le paramètre se trouve dans l’intervalle.
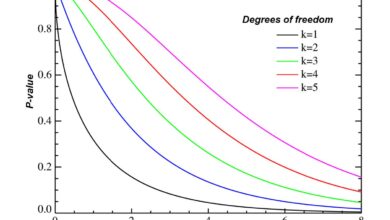
- Tests de signification ou tests d’hypothèse où les scientifiques font une affirmation sur la population en analysant un échantillon statistique. De par sa conception, ce processus comporte une certaine incertitude. Celle-ci peut être exprimée en termes de niveau de signification.
Les techniques que les spécialistes des sciences sociales utilisent pour examiner les relations entre les variables et ainsi créer des statistiques inférentielles comprennent les analyses de régression linéaire, les analyses de régression logistique, l’ANOVA, les analyses de corrélation, la modélisation des équations structurelles et l’analyse de survie. Lorsqu’ils mènent des recherches à l’aide de statistiques inférentielles, les scientifiques effectuent un test de signification pour déterminer s’ils peuvent généraliser leurs résultats à une population plus large. Les tests de signification les plus courants sont le test du chi carré et le test t. Ces tests indiquent aux scientifiques la probabilité que les résultats de leur analyse de l’échantillon soient représentatifs de la population dans son ensemble.
Statistiques descriptives et inférentielles
Bien que les statistiques descriptives soient utiles pour apprendre des choses telles que la répartition et le centre des données, rien dans les statistiques descriptives ne peut être utilisé pour faire des généralisations. Dans les statistiques descriptives, les mesures telles que la moyenne et l’écart-type sont indiquées sous forme de nombres exacts.
Même si les statistiques inférentielles utilisent certains calculs similaires – comme la moyenne et l’écart-type – l’objectif est différent pour les statistiques inférentielles. Les statistiques inférentielles commencent avec un échantillon et se généralisent ensuite à une population. Ces informations sur une population ne sont pas exprimées sous la forme d’un nombre. Au contraire, les scientifiques expriment ces paramètres sous la forme d’une gamme de nombres potentiels, avec un degré de confiance.